




Motivation
------------ ------------
------------
Intelligent phones are widely used recently with the rapid deveopment of requirement of communication among humanbeings. People receives tons of messages everyday which makes them waste time on reading unuseful texts and influences them obtainning important information. The main goal of our project is recognizing spam or ham messages by using appropraite algorithms and machine learning skills. Messages can be classified by using message length, key words in text etc. as numerous special attributes. This project took advantage of several machine learning algorithms and achieved automatically filtering spam messages and keep ham messages with high accuracy.
Data
------------ ------------
------------
The dataset of this project is collected from messages of group members manually and three internet public resources of SMS data. The links of public datasets are shown as follows:
Kdnuggets Dataset Dit Dataset UCI public source
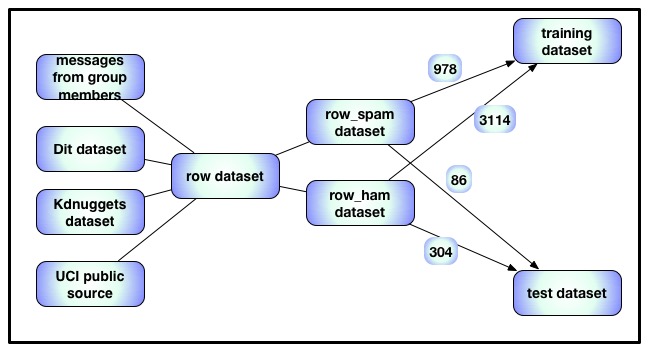
The left graph shown above presents the whole process of collection of data for experiments and attributes. Choosing 978 spam messages and 3114 ham messages and merged them to be the final training dataset from four collected datasets. As for obtaining independent testing dataset from training dataset, 304 ham messages and 86 spam messages were chosen, then merged them as testing dataset. After preprocessing and gaining both training dataset and testing dataset, the ratio of ham messages and spam messages is 3 which is a good proportion. We tried to use the original dataset in our mid-process of project, the result shows not as good as the new dataset with new ration of ham and spam messages.
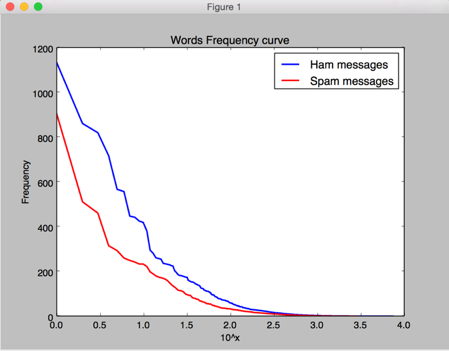
According to the right graph, we choose words with frequency ranks between 10 to 1000 as our attributes.
Algorithm
------------------------
1.Random forests:It is operated by constructing a multitude of decision trees at training time and outputting the class that is the mode of the classes or mean prediction of the individual trees.
2.naivebayes: Given a problem instance to be classified, represented by a vector representing some n features. If the number of features n is large or if a feature can take on a large number of values, then basing such a model on probability tables is infeasible.
3.Decision Tree: It is a flowchart-like structure in which each node represents a "test" on an attribute, each branch represents the outcome of the test and each leaf node represents a class label. The paths from root to leaf represents classification rules.
Experiment
------------------------
We used weka and tried several algorithms to get relatively high-accuracy classifiers and finally 3 classifiers to be considered. Results and learning curves are shown as follows.
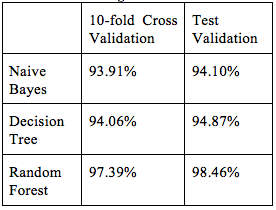
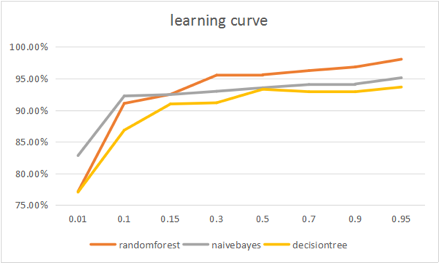
From the result above, “Random Forest” can be the best classifier so far. For more information on validation result, we listed detailed accuracy of Random Forest in report. In addition, the confusion matrix shows that for all 86 spam messages, 2 are falsely classified as ham; and for all 304 hams, 4 are falsely classified as spam.
Conclusion
------------------------
We have now achieved several high accuracy algorithms to recognize spam messages, of which Random Forest is the best. In the future, we can update the attribute vector monthly or annually since spam messages are always being generated. Also, it is feasible to write an app including this algorithm to block spam messages.
